I ❤️ Databases


At the beginning of 2024, I faced a pivotal career question: ‘What do you want to specialize in within the vast field of software engineering?’ After some reflection, I found my answer in databases—not just in administration, but in the engineering of building and maintaining robust data storage systems. My passion for distributed systems naturally led me here, as modern databases, especially distributed ones like TiDB, CockroachDB, MongoDB, Vitess, present some of the most exciting challenges in our field.
Some Distributed Database Challenges
Replication
In order for the database to distribute the query load on multiple storage, it needs to copy the data from data storage to another. As a result, the query load can be distributed cross multiple storages. Basically, replication is about replicating the data from storage to another.
There are three types of replication:
- Single Leader Replication.
- Multi Leaders Replication.
- Leaderless Replication.
There are two server roles in the single and multi-leaders replication:
Primary
Primary the server used for:
- Data changes “DDL” (
INSERT,UPDATE,DELETE) - Retrieve data
SELECT, - Data manipulations “DML” like creating, changing, and deleting database entities like
TABLE,VIEW, Etc.
Furthermore, it also plays the main role in replicating the data to the replica servers.
Replica
Replica used for only retrieving data. It fulfils the SELECT queries.
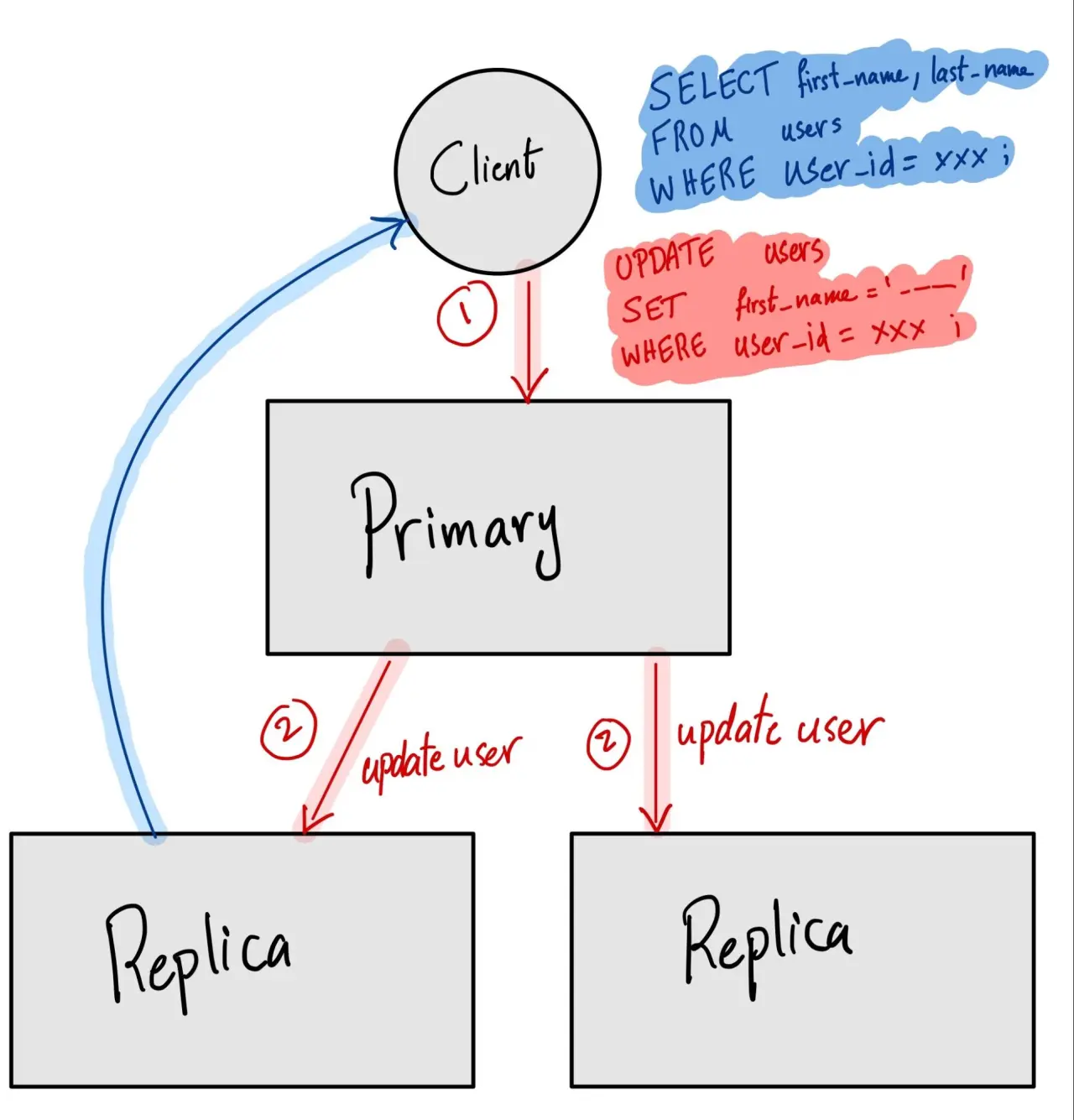
So what are the challenges here?
Data changes are events that applied to the data. It means that it faces the same challenges as an even-driven system, such as how to ensure that things are in sync. What if there is a network congestion? What if the primary storage goes down? Etc.
Partitioning
Most of the modern applications need a data storage. Furthermore, with the recent data revolution, the amount of data stored in the database has increased dramatically. This leads to radically reaching the data storage capacity. The solution for that is the data partitioning (aka sharding). Data partitioning means that you divide the database into small databases. Each set of database system responsible for one or more databases.
There are two types of partitioning:
Vertical Partitioning
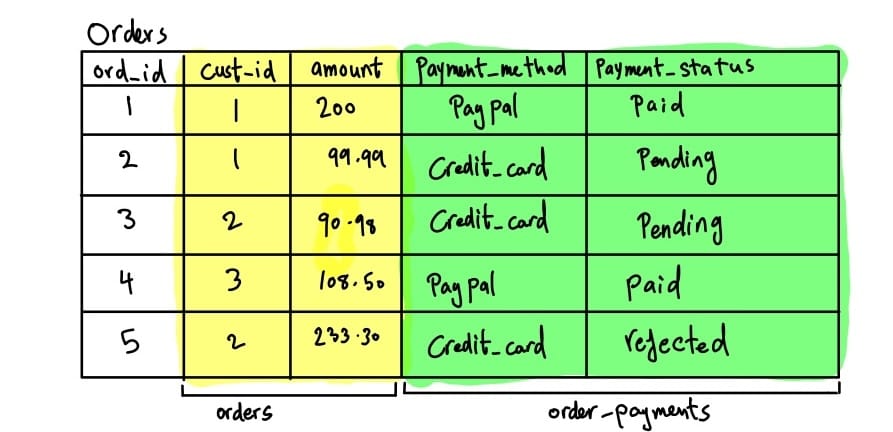
Vertical partitioning is dividing the table vertically, like the table below. You can divide the Orders table into Orders and Order_Payments. The sharding key here is the order_id.
Horizontal Partitioning
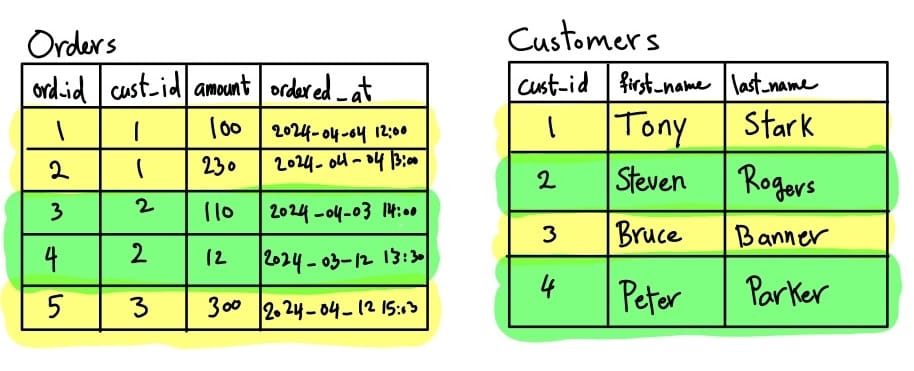
Horizontal partitioning is dividing the table horizontally, like the two tables below. The table partitioned by cust_id based on a simple partitioning rule. The partitioning rule is based-on whether it's an even or odd number. After applying this partitioning, Customers and Order tables for the customers with even IDs stored in a different database than the customers with odd IDs.
So what are the challenges here?
Partitioning is very tricky and risky, you can easily mess it up. Picking a partitioning strategy is hard, and you need to do a proper research before doing it. It's not a one solution fits all.
Hotspots
Even though the partitioning strategy is a naive partitioning strategy, it doesn't mean it's a good strategy. I'll explain why. There is a chance the customers with odd IDs are making orders more than the customers with even IDs. This can lead to uneven partitioning. In some cases, it can lead to hotspots where some partitions contain and handle more data than the other partitions.
Partitioning Key
Picking the partitioning/sharding key is hard, and you can mess it up as well. Let's check the partitioning strategy we applied in the horizontal partitioning example above again. What makes the cust_id a better partitioning key than the order_id?
I don't really know 🤷🏻 because there is no perfect or correct answer here. The answer should be based on the data access and creation patterns.
Final Words
This article provides a brief overview of some of the obstacles that must be overcome when working with distributed databases. This is a tip of the iceberg. Some people consider them to be a headache, but I see them as challenges. This kind of challenge has no one solution, you need to understand the exact situation of the problem and find the good enough solution for now and how to reach the perfect solution in the future. It's like treating the database as a product, and you have to keep improving and maintaining it.




