Unlock AI's Hidden Power: 5 Steps to Build a RAG System That Beats Fine-Tuning!


When the GenAI revolution started, some companies started to see the opportunity to use GenAI. From improving the customer support experience to automating repetitive tasks. Unfortunately, there is a big problem, which is the pre-trained models are either outdated (trained on last year's data) aka cutoff date, or they're missing the companies' private and public data. If the company needs to train the pre-trained models on their data, they need to do model fine-tuning. The fine-tuning comes with complications as it's a GPU intensive operation. Using private GPUs means paying the full cost, including underutilization, power consumption, and maintenance. On the other hand, if you use cloud-based GPUs, then you are saving costs, but you are compromising your own data. Why? Because you need to send the training dataset to the cloud in order to fine-tune the model.
Here comes RAG to bring the best of both worlds. Let's talk about RAG in detail.
What is RAG?
Let's check the definition from Wikipedia:
Retrieval Augmented Generation (RAG) is a technique that grants generative artificial intelligence models information retrieval capabilities. It modifies interactions with a large language model (LLM) so that the model responds to user queries with reference to a specified set of documents, using this information to augment information drawn from its own vast, static training data. This allows LLMs to use domain-specific and/or updated information.[1] Use cases include providing chatbot access to internal company data or giving factual information only from an authoritative source.[2] ~ Wikipedia
In simple English, RAG is a way to add more context to the model so that it can give a precise response, "this depends on context quality". In other words, you are forcing the model to answer based on the context you provided to it.
Why do you need a RAG?
Now that we know what a RAG is, we need to know why we require a RAG. There are several reasons when you might need a RAG.
Closed-source model
Some AI models are closed source, which means that you are dealing with a black-box where you don't know what is happening internally and how the model and the AI company are handling your data and how it's making decisions. Example: OpenAI's GPT-4o model.
Data Privacy
You are sending your private data to the AI model owner/host company. Do they store it? Do they use it for training the model?
Lack of GPUs/Hardware
Not every company has access to GPUs to fine-tune the pre-trained models. The easy solution is to provide the related context to the model.
Cost
One fine-tuning won't cost much, but if you need to do it to cope with the data changes, it'll cost a lot.
Faster Data Change
You are using your data to build the RAG. It can use any source of data and transform it into vectors (we'll discuss later). Once you update your data, the RAG should be updated as well.
The Five Steps To Build a RAG
Step 1: Data Collection
This is an essential step in building RAG systems. Data collection involves gathering the data that will be used in the RAG system. The following are some key considerations for data collection:
- Identify the data sources: Identify the data sources that are relevant to your use case. This could include internal documents, databases, APIs, or external data sources.
- Data format: Ensure that the data is in a format that can be easily processed. Common formats include text files, CSV, JSON, or databases.
- Data quality: Ensure that the data is clean, accurate, and relevant. This may involve data cleaning, deduplication, and normalization.
- Data storage: Store the data in a way that is easily accessible for processing. This could be a database, a file system, or a cloud storage solution.
- Data access: Ensure that you have the necessary permissions and access to the data sources. This may involve setting up API keys, authentication, or data sharing agreements.
- Data security: Ensure that the data is stored securely, and that sensitive information is protected. This may involve encryption, access controls, and compliance with data protection regulations.
Step 2: Data Chunking
Data chunking is the process of breaking down large documents or datasets into smaller, manageable pieces. This is important for several reasons:
- Efficiency: Smaller chunks are easier to process and analyze, which can improve the performance of the RAG system.
- Relevance: Smaller chunks can help to ensure that the most relevant information is retrieved and used in the RAG system.
- Context: Smaller chunks can help to provide more context for the RAG system, which can improve the quality of the generated responses.
- Scalability: Smaller chunks can help to ensure that the RAG system can scale to handle larger datasets or documents.
- Flexibility: Smaller chunks can be easily combined or recombined to create different views or perspectives on the data.
- Maintainability: Smaller chunks can be easier to maintain and update, which can help to ensure that the RAG system remains relevant and up-to-date.
Step 3: Data Embedding
Data Embedding
Data embedding is the process of converting data into a numerical representation that can be used by GenAI models. In this step, you need to use an embedding model. There are two types of embedding models:
- Open source: You can use open-source models like Sentence Transformers or Hugging Face, or Ollama's embedding models.
- Closed-source: You can use closed-source models like OpenAI's text-embedding-ada-002.
Embedding Models
When choosing an embedding model, consider:
- Dimensionality: Higher dimensions can capture more information but require more storage and computation.
- Domain-specific vs. general embeddings: Some embedding models are trained for specific domains (legal, medical, etc.) and may perform better for specialized content.
- Semantic similarity: How well the embedding captures true semantic relationships rather than just lexical similarities.
Techniques like dimensionality reduction (PCA, t-SNE) can sometimes be applied to balance performance and resource usage.
Vector Database
After generating the embeddings, you need to store them in a vector database. There are many vector databases available, such as:
Step 4: Handling User Queries
In handling user queries, you don't send the user query directly to the GenAI model. Instead, you need to do the following:
- Preprocess the user query: Preprocess the user query to ensure that it is in a format that can be used by the vector database. This may involve tokenization, normalization, or other preprocessing steps.
- Query the vector database: Use the user query to search the vector database for relevant chunks of data. This is typically done using a similarity search algorithm, such as cosine similarity or Euclidean distance.
- Retrieve the top N results: Retrieve the top N most relevant chunks of data from the vector database. The value of N will depend on your use case and the amount of data you have.
- Combine the results: Combine the retrieved chunks of data into a single context. This may involve concatenating the text, summarizing the information, or selecting the most relevant pieces of information.
- Format the context: Format the combined context in a way that is suitable for the GenAI model. This may involve adding prompts, instructions, or other contextual information.
Step 5: Agent Response Generation
After you have the context, you need to include it in the prompt you send to the GenAI. After that, you wait for the GenAI model to generate a response.
Diagram
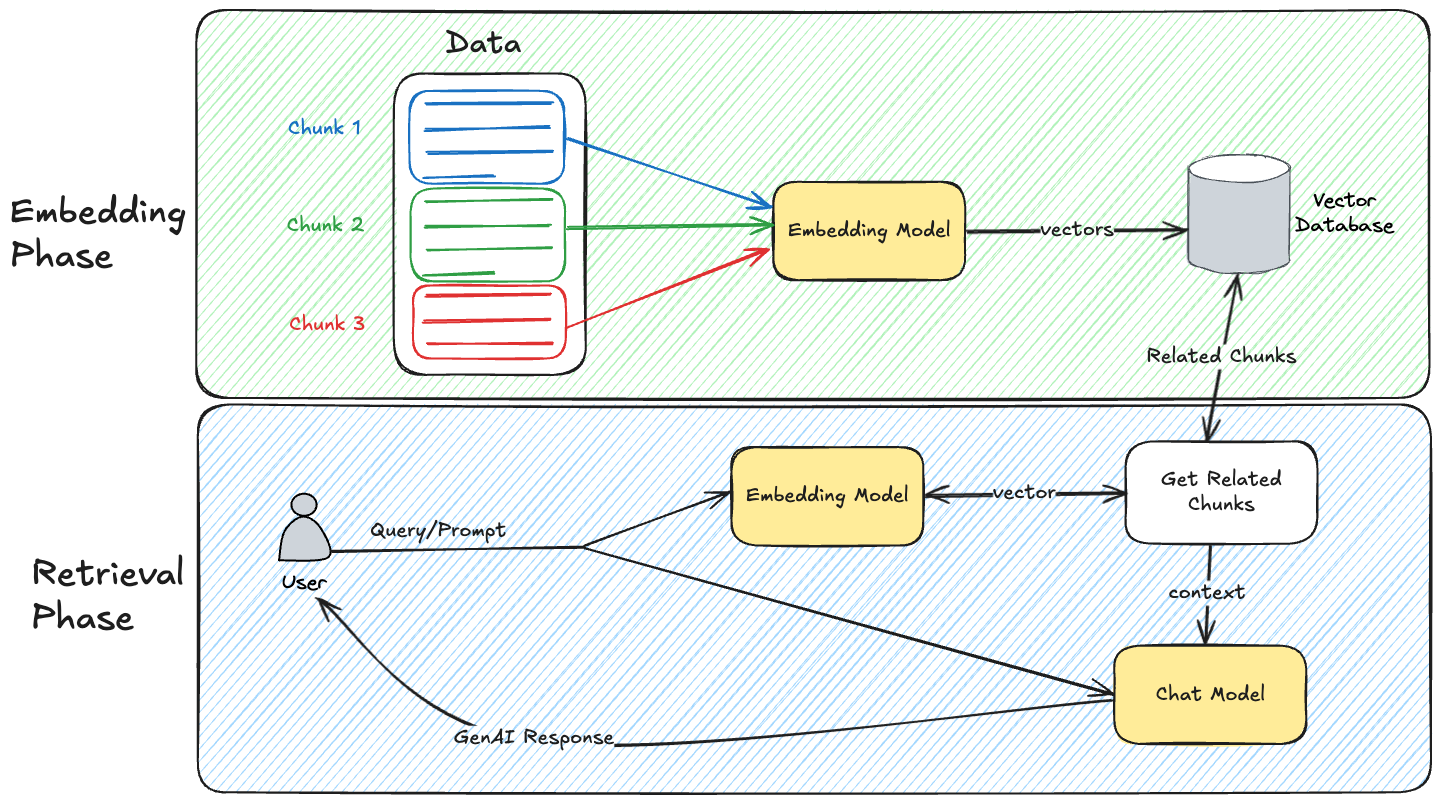
Conclusion
In this article, we discussed the RAG system and how to build it. We explored the five steps to build a RAG system. RAG is a powerful tool. It can improve your GenAI models' performance. It provides more relevant and accurate responses.
Building a RAG system requires careful planning. Implementation can be challenging. Yet, with the right tools and techniques, you can succeed. Your RAG system can meet your specific needs. It will provide significant value to your users.




